Datafundament
Datafundament[bewerken]
Het datafundament is de omgeving binnen een organisatie waarin gegevens en documenten worden verwerkt tot bruikbare informatie voor zowel intern als extern gebruik. Met betrekking tot het verwerken van gegevens is het van belang om te weten op welk niveau binnen het datafundament de acties zijn uitgezet om te komen tot bruikbare informatie en op welk niveau binnen het datafundament deze activiteiten plaatsvinden. Zie daarvoor Processen, hoofdstuk Bedrijfsprocesinteracties.

Type(n)data[bewerken]
Binnen het gegevensmanagement wordt vaak gebruik gemaakt van het begrip 'brondata'. 'Brondata' is echter een begrip wat alleen iets zegt over de input en output. Niet over wat er is gebeurd met de data, of de kwaliteit van de data.
Binnen de waterschappen onderscheiden we de volgende categorieën (bron)data:
- ruwe / initiële data
- gevalideerde data
- geaggregeerde data
- analyse data
De onderstaande figuur toont de samenhang tussen de verschillende categorieën .
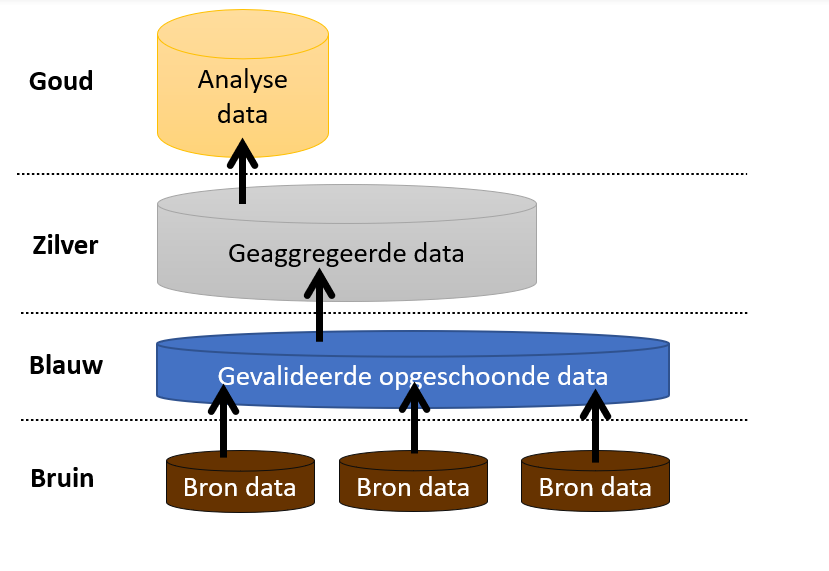

NB. Daar waar gesproken wordt over 'data' kan natuurlijk ook het begrip 'gegevens' gebruikt worden.
In communicatie met niet data gerelateerde professionals helpt het om op een eenvoudige wijze dezelfde taal te spreken. Zoals de Inuït meerdere variaties kent voor het woord sneeuw, zo zien medewerkers die werken met data meerdere variaties aan brondata. Gevalideerde data kent bijvoorbeeld ook meerdere betekenissen. Vandaar dat er onderscheid gemaakt wordt in verschillende typen 'brondata' (of brongegevens) met behulp van kleur. Hierin wordt specifiek aangegeven wat er met de data is gebeurd.
Bruine data[bewerken]
Dit is ruwe data (of een exacte kopie ervan) die tijdens het inwinnen wordt vastgelegd. Het inwinnen kan bijvoorbeeld gebeuren door een landmeter of gegevensbeheerder. De data wordt fysiek gecontroleerd, om te kijken of de informatie correct is. Daarna wordt het opgevoerd in het register.
Blauwe data[bewerken]
Ook wel: 'opgeschoonde data' genoemd. Dit is de data die kwantitatief gevalideerd en geconformeerd is. Soms wordt deze data ook geverifieerd. De input komt altijd uit de bruine datalaag. Deze datalaag is geschikt om als centrale feitelijk correcte data meerdere keren in de organisatie te gebruiken. Deze laag wordt de 'single source of truth' genoemd. Ook wel centrale Distributielaag genoemd.
- Validatie: alle handelingen om er voor te zorgen dat de data juist, tijdig en volledig zijn.
- Conformatie: alle activiteiten die er op gericht zijn om eenduidigheid van je gegevens in je organisatie te krijgen. Dat geolocaties bijvoorbeeld uniform worden weergegeven op dezelfde manier.
- Verificatie: alle controles die er op gericht zijn om ervoor te zorgen dat valse uitschieters, of rekenfouten niet in je dataset voorkomen.
Voorbeelden van validatie op kwantiteit zijn:
- Klopt de geolocatie-opbouw van een string coördinaten?
- Is tijdigheid in acht genomen of verlopen?
- Is de dataset volledig?
Onder conformatie wordt bijvoorbeeld verstaan:
- Aanpassen aan Aquo-standaarden geldend binnen het waterschap.
- Opbouw van kolommen aanpassen aan standaarden die binnen het waterschap zijn afgesproken.
- UTF-16 codering terugbrengen naar UTF-8.
- Geografische waarden van ESRI-formaat omzetten naar open source-formaat.
Onder verificatie wordt bijvoorbeeld verstaan:
- Klopt de geolocatie topologisch? (bijvoorbeeld watergang)
- Is de meetwaarde ook conform wat verwacht mag worden? Dit is in relatie tot andere meetwaarden die nagenoeg gelijktijdig plaatsvinden en technische uitschieters filteren.
Zilveren data[bewerken]
Dit is zogeheten geaggregeerde data. In deze laag wordt data gereed gemaakt en gebruikt om analyses te doen. Datasets kunnen worden
- gefilterd
- gecombineerd
- samengevoegd
- ingedikt
- gecategoriseerd
- op een andere manier gepresenteerd
- herschikt
- getransponeerd
- etc.
De input van deze data is bij voorkeur de blauwe laag. Deze data wordt gebruikt ter ondersteuning van het beschrijven en opstellen van verklarende statistische analyses en modellen, al dan niet geautomatiseerd.
Gouden data[bewerken]
Deze data ontstaat door gebruik te maken van:
- Artificial Intelligence
- Machine learning
- Data mining
- Andere technieken uit de data science die analyses veelvuldig herhalen en de resultaten wegschrijven in een separate dataset
Daar waar de 'bruine laag' een weergave is van feitelijk waarneembare objecten en subjecten, is de gouden laag alleen gebaseerd op de digitale werkelijkheid. Deze digitale werkelijkheid is alleen aanwezig in het datalandschap.
Gouden data kan zowel de bruine laag, als de blauwe en zilveren laag als input hebben. Al naar gelang (1) het doel van de analyse en (2) de betrouwbaarheidseis zal gebruik worden gemaakt van de desbetreffende laag.
Voorbeelden:
- Wanneer de betrouwbaarheid van meetwaarden wordt geanalyseerd in een RWZI om daar in het proces geautomatiseerd een keuze te laten maken, zal rechtstreeks de bruine laag als input worden gebruikt.
- Wanneer het oppervlaktewater geoptimaliseerd moet worden en scenario's worden uitgewerkt, zal bijvoorbeeld de blauwe laag worden gebruikt.